Take a look at the crash data for 11th street in the Houston Heights
Author
Alan Jackson
Published
April 12, 2025
11th Street Crash Data
11th street in the Houston Heights was reduced from 4 lanes to two, with the addition of protected bicycle lanes, between October 2022 and January 2023. The primary goal was to calm the traffic on 11th and get people to drive the speed limit as it had become quite dangerous.
The portion of the street that was re-engineered went from the intersection at Shepherd east to the end of the street at Michaux.
Now that we have 2 years of data from TxDoT on crashes, we can look at how effective the changes may have been.
Let’s pull out eleventh street and do some data cleanup
There are some obvious typos in the street names and block numbers Also there are missing lat longs, so we will just calculate our own for everywhere, since I don’t know what geoid was used for these anyway.
Code
# Pull out 11th street and do some cleanupEleventh <- df %>%filter(City=="Houston") %>%filter(stringr::str_detect(Rpt_Street_Name, "11 ?TH")) %>%mutate(Rpt_Street_Name=stringr::str_remove(Rpt_Street_Name, "E | ST| 12| ")) %>%mutate(Severity=factor(Severity, levels=c("NOT INJURED", "POSSIBLE INJURY","NON-INCAPACITATING", "SUSPECTED SERIOUS INJURY","FATAL", "UNKNOWN"))) %>%mutate(Harmed=factor(Harmed, levels=c("Motor Vehicle in Transport","Fixed Object", "Parked Car","Pedestrian", "Pedal Cyclist","Overturned", "Other Object", "Animal","Other Non-Collision", "Rail Road"))) %>%# Get some of the missing block numbersmutate(Rpt_Block_Num=if_else(is.na(Rpt_Block_Num), as.character(100*as.integer(as.numeric(Street_Nbr)/100)), Rpt_Block_Num))
Geocode addresses
About 20% of the records have no lat-long attached, so I will geocode the records to fill in those blanks. There are two records where there is no block number, so those will be dropped as there is no way to know where on 11th street they are.
Code
Exact_match <-NULLFailed_match <-NULLEleventh <- Eleventh %>%filter(!is.na(Rpt_Block_Num)) %>%filter(!is.na(Rpt_Street_Pfx)) %>%mutate(Zipcode="77008") %>%mutate(Rpt_Street_Sfx="ST") %>%mutate(Rpt_Block_Num=stringr::str_replace(Rpt_Block_Num, "..$", "25")) %>%mutate(Zipcode=if_else((Rpt_Street_Pfx=="E")&(as.integer(Rpt_Block_Num)>=1100), "77009", "77008"))# Exact matchesfor (i in1:nrow(Eleventh)){ # first look for exact matches tmp <-match_exactly(Eleventh[i,]$Rpt_Block_Num, Eleventh[i,]$Rpt_Street_Pfx, Eleventh[i,]$Rpt_Street_Name, Eleventh[i,]$Rpt_Street_Sfx, Eleventh[i,]$Zipcode)if (tmp$Success){ # success Exact_match <-cbind(Eleventh[i,], tmp) %>%select(Crash_ID, Rpt_Block_Num, Rpt_Street_Pfx, Rpt_Street_Name, Rpt_Street_Sfx, Zipcode, Lat, Lon) %>%rbind(., Exact_match) } else { # Fail exact match Failed_match <-cbind(Eleventh[i,], tmp) %>%select(Crash_ID, Rpt_Block_Num, Rpt_Street_Pfx, Rpt_Street_Name, Rpt_Street_Sfx, Zipcode, Fail, Lat, Lon) %>%rbind(., Failed_match) }}# add a field to hold the corrected data if anyFailed_match <- Failed_match %>%mutate(Correction=NA)# Repair numberfor (i in1:nrow(Failed_match)){ target <- Failed_match[i,] tmp <-repair_number(target$Rpt_Block_Num, target$Rpt_Street_Pfx, target$Rpt_Street_Name, target$Rpt_Street_Sfx, target$Zipcode, Distance=550)if (tmp$Success){ # success Failed_match[i,]$Lat <- tmp$Lat Failed_match[i,]$Lon <- tmp$Lon Failed_match[i,]$Correction <- tmp$Result } else { Failed_match[i,]$Fail <-paste("Street_num",tmp$Fail) }}# pull out failed matchesMatches <- Failed_match %>%filter(Lat>0) %>%select(-Correction, -Fail) %>%rbind(., Exact_match)Failed_match <- Failed_match %>%filter(Lat==0) %>%mutate(Rpt_Block_Num=stringr::str_replace(Rpt_Block_Num, "..$", "24")) # Repair numberfor (i in1:nrow(Failed_match)){ target <- Failed_match[i,] tmp <-repair_number(target$Rpt_Block_Num, target$Rpt_Street_Pfx, target$Rpt_Street_Name, target$Rpt_Street_Sfx, target$Zipcode, Distance=550)if (tmp$Success){ # success Failed_match[i,]$Lat <- tmp$Lat Failed_match[i,]$Lon <- tmp$Lon Failed_match[i,]$Correction <- tmp$Result } else { Failed_match[i,]$Fail <-paste("Street_num",tmp$Fail) }}# pull out failed matchesMatches <- Failed_match %>%filter(Lat>0) %>%select(-Correction, -Fail) %>%rbind(., Matches)Failed_match <- Failed_match %>%filter(Lat==0) # Add new lat longs to master fileEleventh <- Matches %>%select(Crash_ID, Lat, Lon) %>%left_join(Eleventh, ., by="Crash_ID")# Dump remaining unknown lat/longs for hand editsfoo <- Eleventh %>%filter(is.na(Lat) &is.na(Latitude))Eleventh[Eleventh$Crash_ID=="19420144",]$Lat <-29.789750981741Eleventh[Eleventh$Crash_ID=="19420144",]$Lon <--95.42065368245Eleventh[Eleventh$Crash_ID=="19519095",]$Lat <-29.789750981741Eleventh[Eleventh$Crash_ID=="19519095",]$Lon <--95.42065368245Eleventh[Eleventh$Crash_ID=="19112620",]$Lat <-29.790612430221Eleventh[Eleventh$Crash_ID=="19112620",]$Lon <--95.39807436273Eleventh[Eleventh$Crash_ID=="18449355",]$Lat <-29.790612430221Eleventh[Eleventh$Crash_ID=="18449355",]$Lon <--95.39807436273Eleventh <- Eleventh %>%mutate(Lat=if_else(is.na(Lat), as.numeric(Latitude), Lat)) %>%mutate(Lon=if_else(is.na(Lon), as.numeric(Longitude), Lon))
Overall statistics
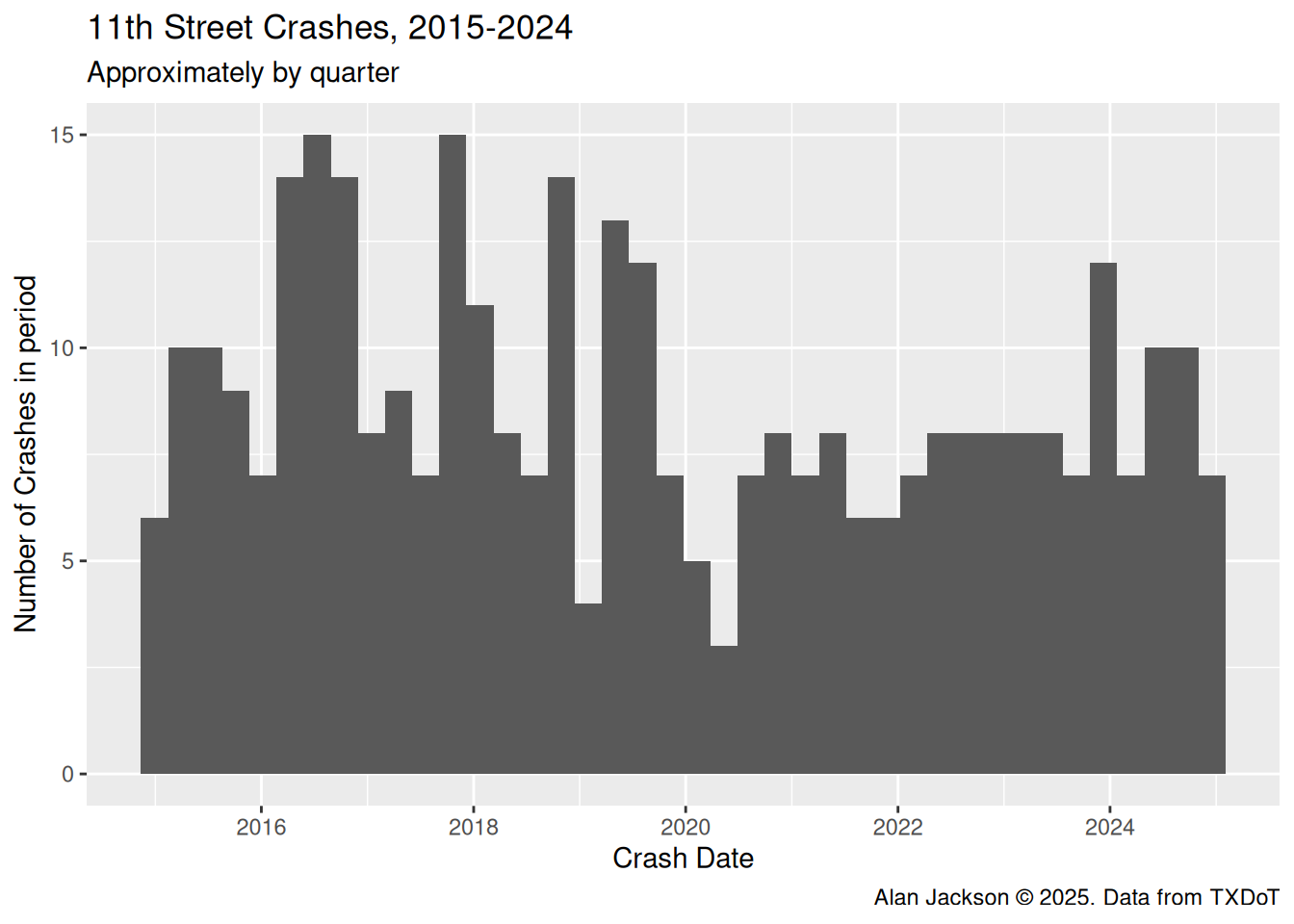
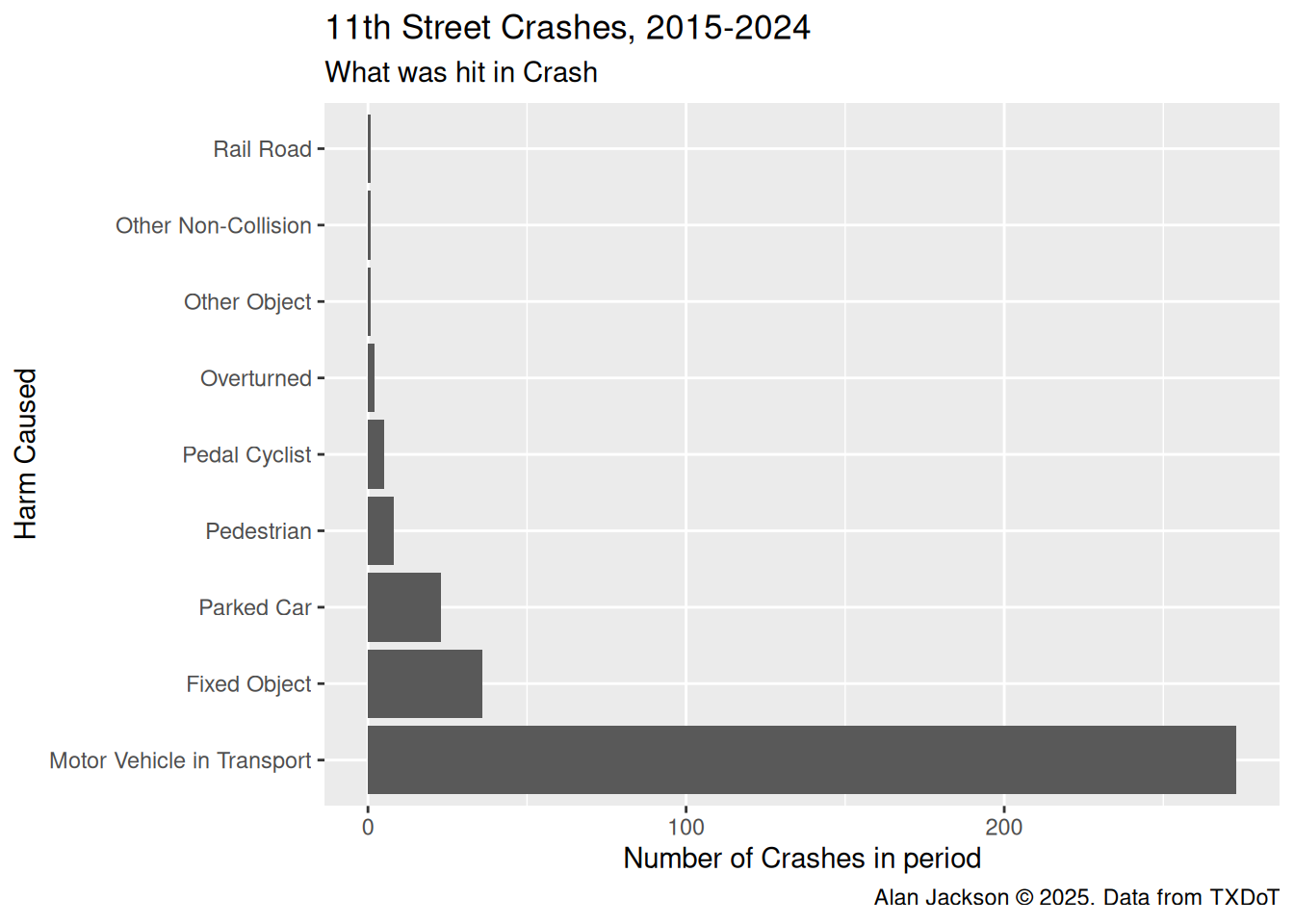
Let’s begin by simply looking at some overall statistics, to get a feel for the data.
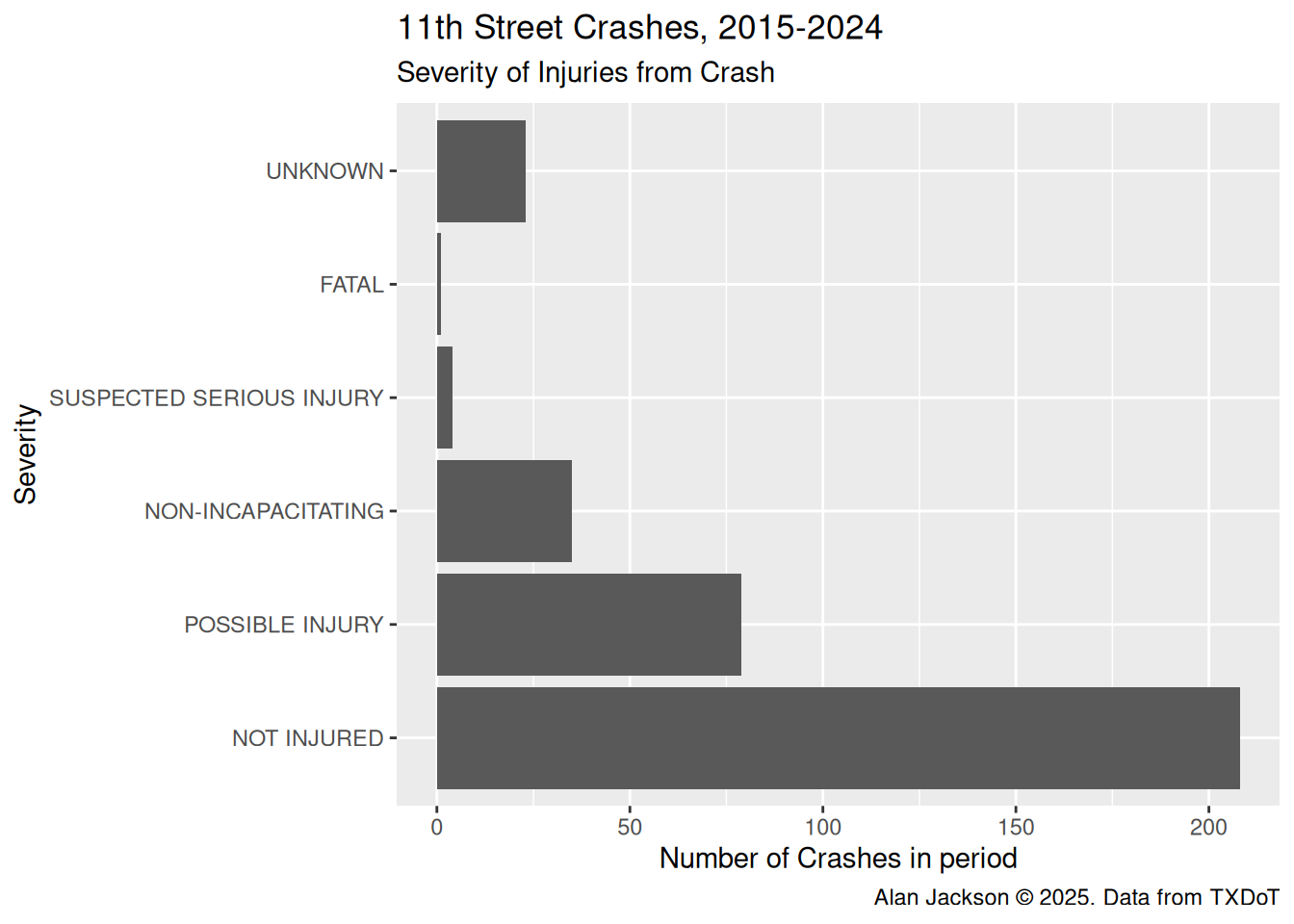
It looks like about 50% of the reported crashes resulted in injuries, although selection bias is certainly at work here. Crashes without an injury are much less likely to get reported at all.
Here is a random selection of records from the raw dataset.
Distribution of the severity of injuries. Note that it is likely that crashes in which no one is injured are much more likely to not be reported, so those numbers are probably low.
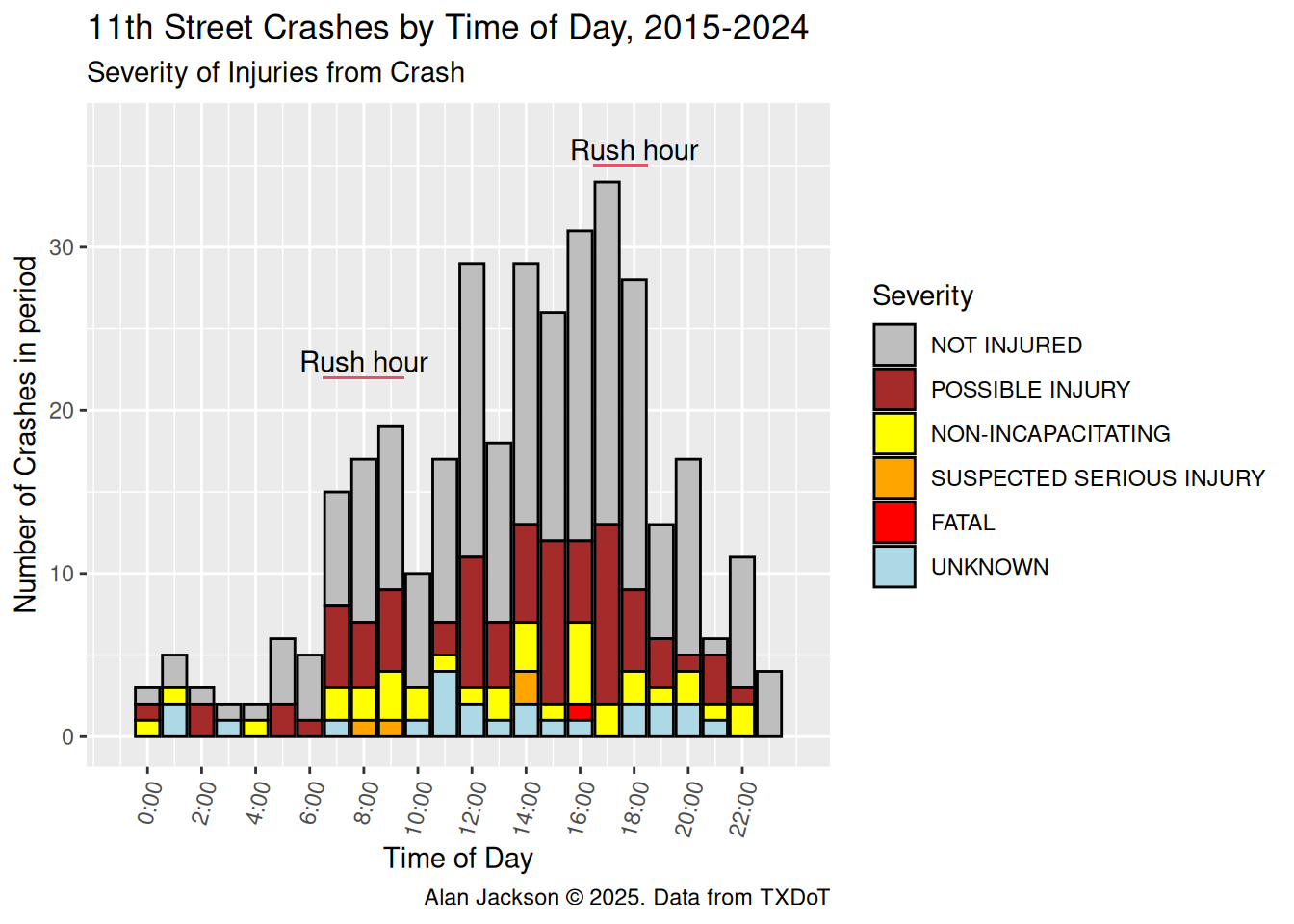
From noon until rush hour seems to be the most dangerous time, although except for the early morning hours, the fraction of crashes resulting in injury seems roughly constant.
Let’s add a field to flag where the bike lanes are
The bike lanes run from Shepherd on the west, to Michaux on the east.
Code
Eleventh <- Eleventh %>%mutate(Calm=TRUE) %>%mutate(Calm=if_else(Lon<-95.40986818316094, FALSE, Calm)) %>%mutate(Calm=if_else(Lon>-95.38434146384971, FALSE, Calm)) # Round off block numbers again and add a block counterfoo_w <- Eleventh %>%arrange(Lon) %>%mutate(Rpt_Block_Num=stringr::str_replace(Rpt_Block_Num, "..$", "00")) %>%filter(Rpt_Street_Pfx=="W")foo_e <- Eleventh %>%arrange(Lon) %>%mutate(Rpt_Block_Num=stringr::str_replace(Rpt_Block_Num, "..$", "00")) %>%filter(Rpt_Street_Pfx=="E")# For blocks west of HeightsCounter_w <-tibble(Block=(40:1)*100) %>%mutate(Counter=row_number()) %>%mutate(Prefix="W")# For blocks east of HeightsCounter_e <-tibble(Block=(1:11)*100) %>%mutate(Counter=row_number()+40) %>%mutate(Prefix="E")Counter <-rbind(Counter_w, Counter_e) %>%mutate(Block=as.character(Block)) %>%mutate(Counter=factor(as.character(Counter), levels=(as.character(Counter))))keep <- EleventhEleventh <- Eleventh %>%mutate(Rpt_Block_Num=stringr::str_replace(Rpt_Block_Num, "..$", "00")) %>%inner_join(., Counter, join_by(Rpt_Block_Num==Block, Rpt_Street_Pfx==Prefix))saveRDS(Eleventh, "Eleventh_data.rds")
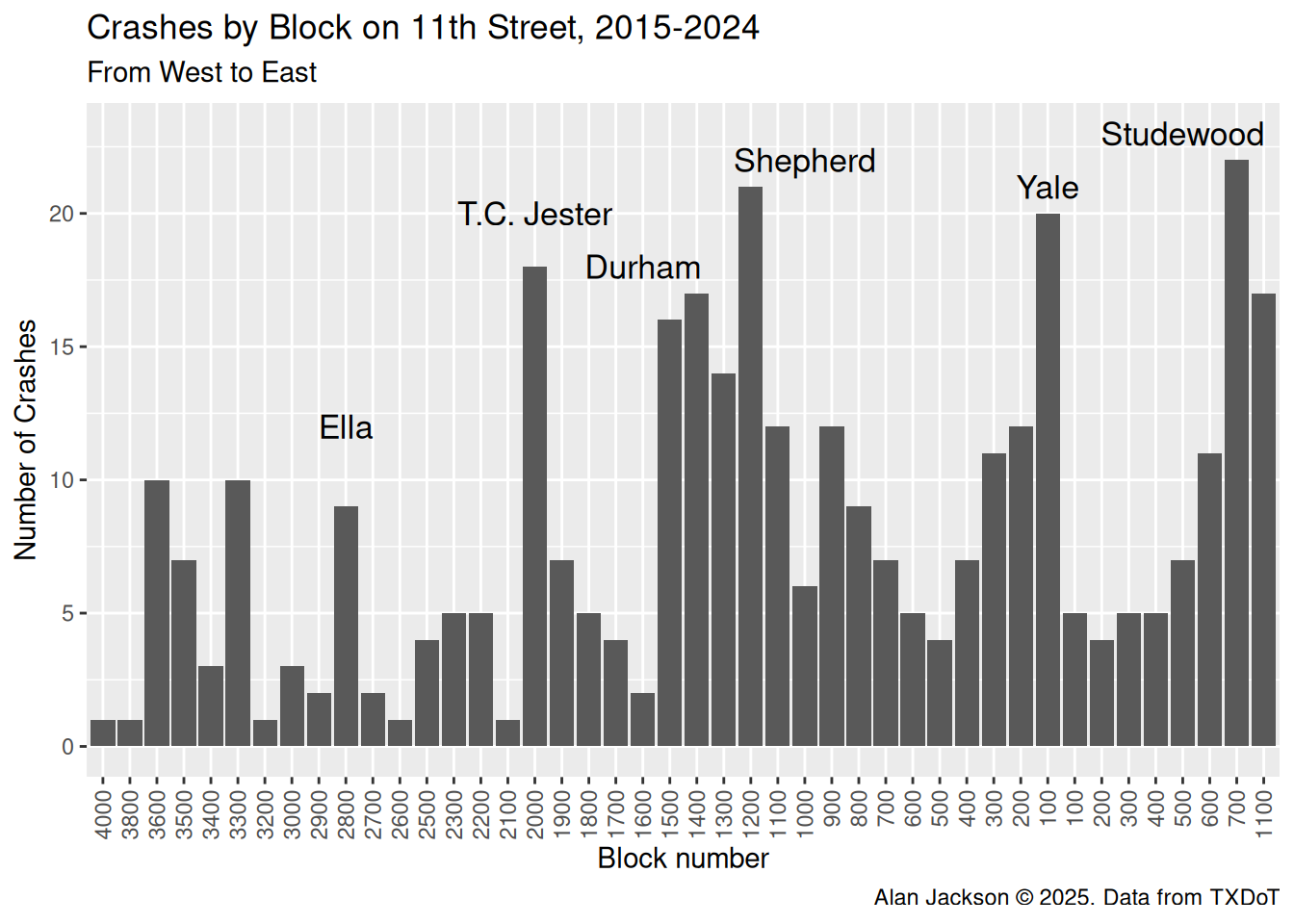
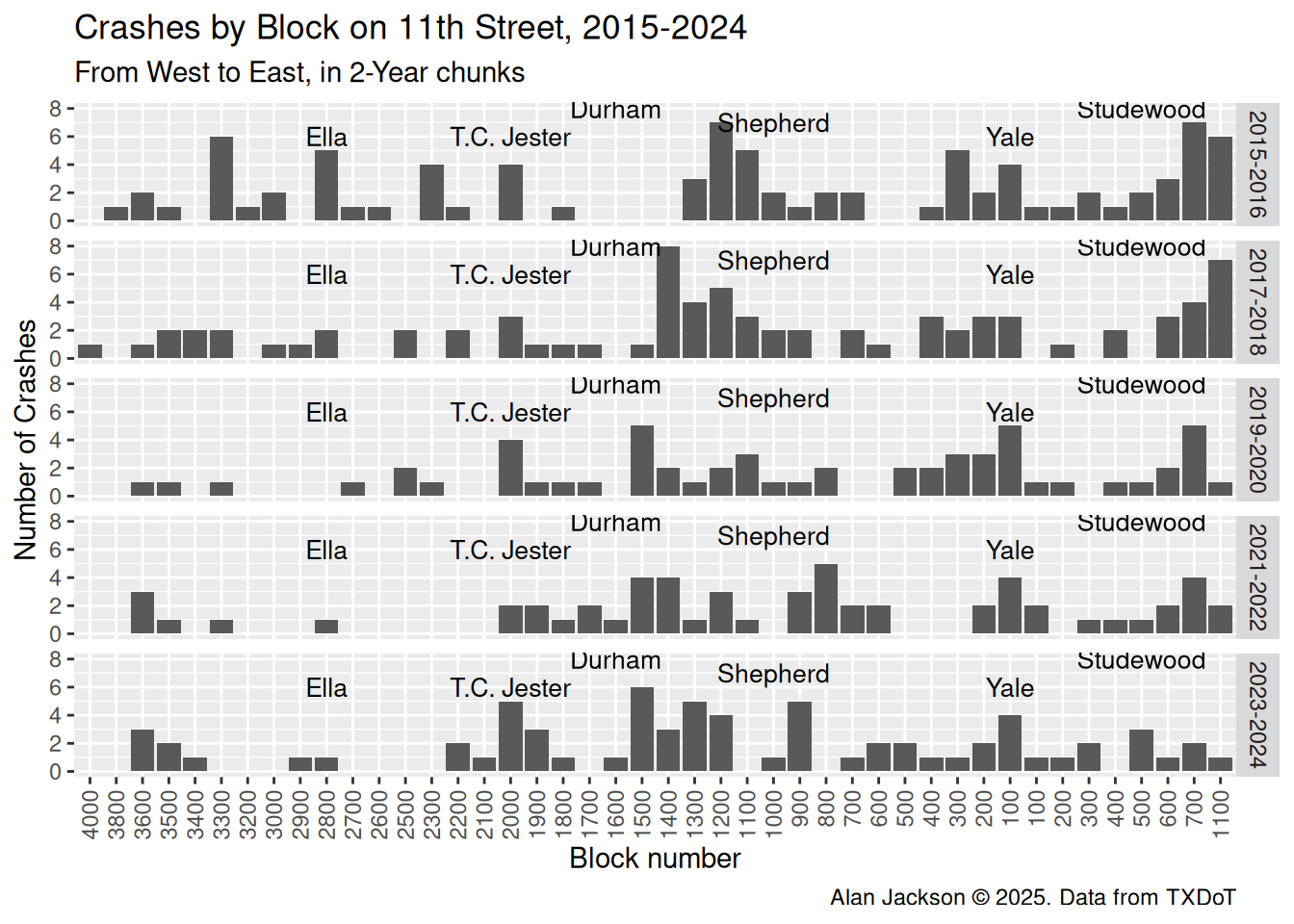
Let’s plot the data from west to east
It clear from this plot why the eastern half of 11th was targeted for traffic calming. A significant number of crashes in that portion of the steet. The part west of Shepherd is a boulevard - which may be why it has seen significantly fewer crashes.
It seems pretty clear that the number of crashes east of Shepherd - the part of 11th that was “calmed” - has seen fewer crashes than it was seeing historically.
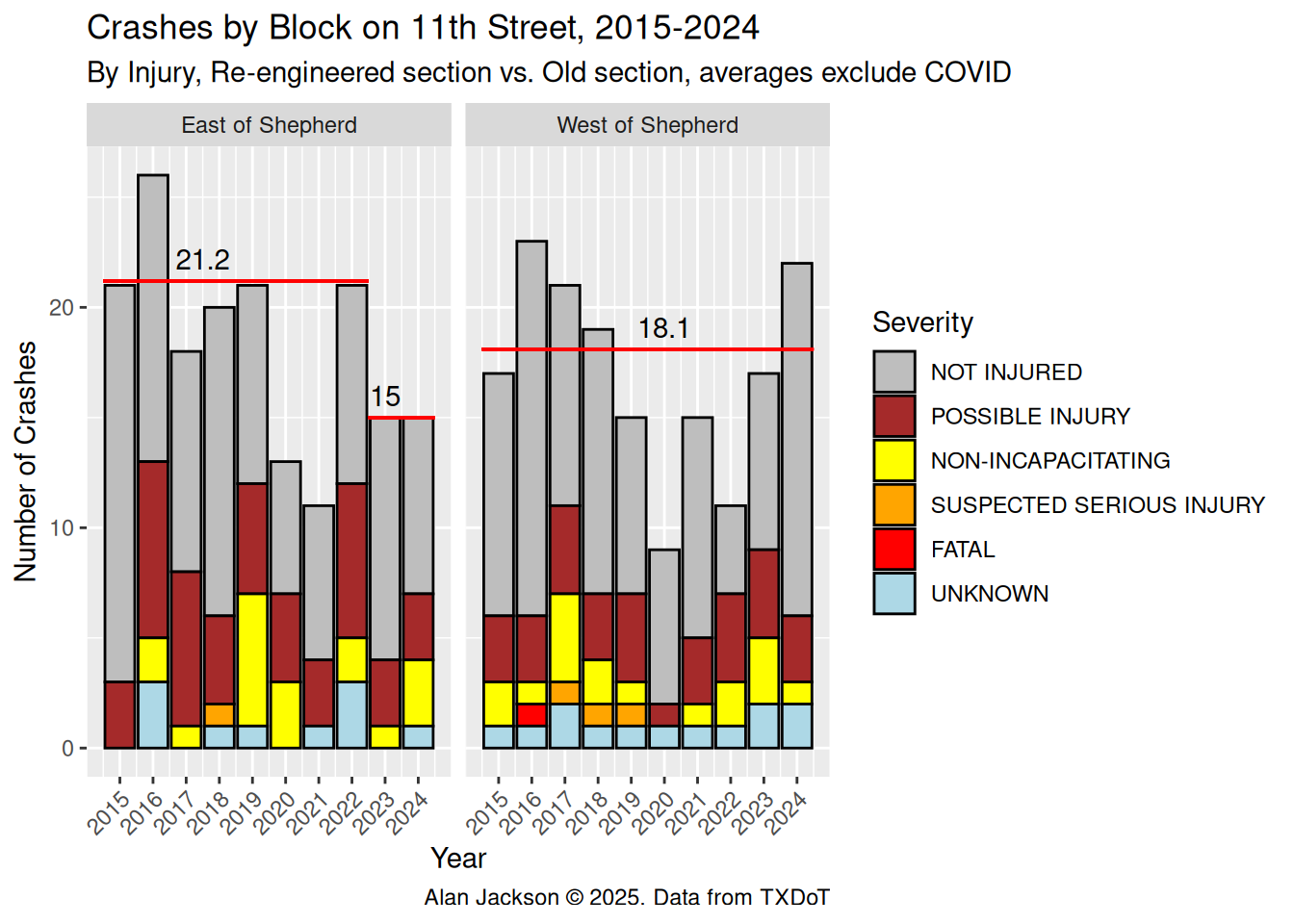
Let’s look at the sum of crashes per year, colored by injury
It is pretty clear that in the “calmed” portion of 11th the number of crashes has declined, but more inportantly, the number of crashes resulting in injuries has dropped - almost certainly a result of lower impact speeds. We do not see a similar decline west of Shepherd.
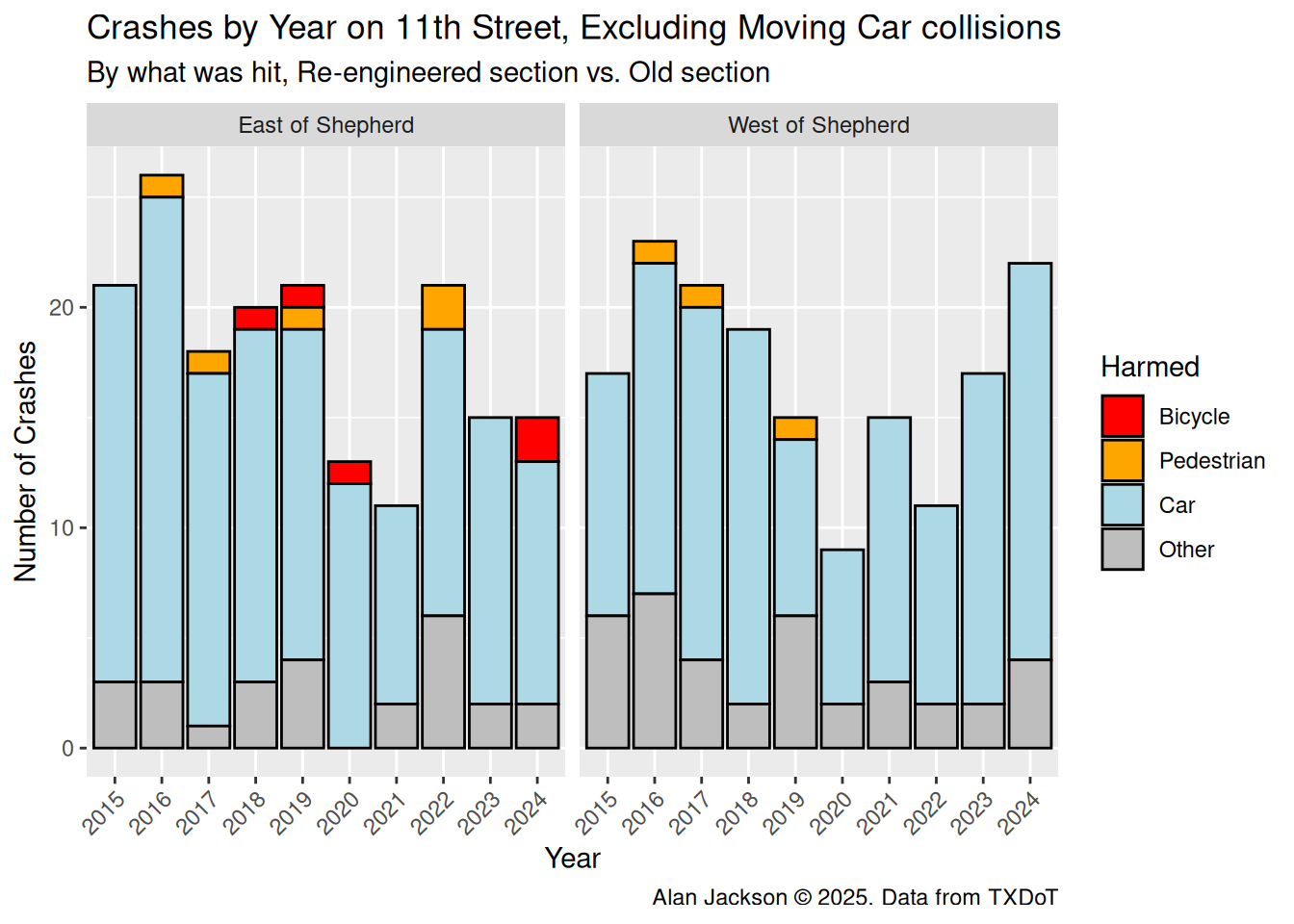
Let’s look at the sum of crashes per year, colored by harm
It is pretty clear that in the “calmed” portion of 11th the number of crashes has declined, but more inportantly, the number of crashes resulting in injuries has dropped - almost certainly a result of lower impact speeds. We do not see a similar decline west of Shepherd. Note that 2020 and 2021 were the COVID years.
From this data, it appears that the main goal of the re-engineering - traffic calming to reduce crashes and reduce the impact of crashes - was largely successful.
Excluding the COVID years, West of Shepherd saw an average of 18.1 crashes per year in the 2015-2024 period. East of Shepherd - again excluding COVID years - crashes declined from 21.2 per year to 15.0 per year, a decline of 30%.
The data on bicyclists and pedestrians is too sparse for a meaningful statistical analysis, but it does hint at injuries becoming less severe. In any event, it is notable that almost all the collisions with bicycles or pedestrians resulted in injuries, highlighting the unequal nature of the interaction.